Archived Entry
数学题库知识库的制作流程:从一道题到可反查、可分层、可分析的知识系统
数学题库知识库的制作流程:从一道题到可反查、可分层、可分析的知识系统
从开源题库到可反查、可分层、可分析的数学知识系统
开篇致谢
这个数学题库知识库项目主要建立在 MathNet 开源题库的基础之上。首先要感谢 MathNet 的建设者和所有参与者,是他们长期整理、校对、收集并开放这些数学题目,才让后续的知识库整理、步骤拆解和知识点反查成为可能。
特别感谢 Navid。题库的积累不是短时间内可以完成的工作,长期收集题目、维护数据、整理来源、不断补充内容,是非常辛苦也非常有价值的事情。正是因为有这样多年持续投入的基础工作,后来者才有机会在这些题目之上继续做结构化、知识图谱和教学应用方面的探索。
本文介绍的不是一个从零开始造题库的过程,而是在已有开源题库基础上,把题目、答案、步骤和知识点重新组织成可查询、可反查、可分层教学使用的数据结构。

一、为什么要做这样的数学题库知识库
传统题库最常见的结构是:
题目答案解析分类难度
比如,一道题被标成“组合题”,但它的解题过程里可能同时用到了:
数学归纳法鸽巢原理最坏情况构造反证法奇偶性观察图连通性思想
如果题库只保存“组合”这个分类,那么系统并不知道这道题到底为什么难,也不知道孩子做不出来是卡在哪一步。
孩子错了一道题,传统题库最多只能说:
这是一道组合题。
但真正有价值的分析应该是:
这道题第 13 步用了鸽巢原理;第 15 步用了结构分类讨论;第 17 步用了反证法;第 19 步用了图连通性的替代证明;孩子可能不是不会组合,而是没有掌握“下界证明中的反证构造”。
这就是这个项目的核心意义:不是简单地收集题目,而是把题目拆成可以理解、可以查询、可以统计、可以教学使用的知识结构。
二、知识点反查对教学的意义
我最看重的是“知识点反查题目”这个能力。
普通题库一般是从题目出发:
打开一道题 → 看答案 → 看解析而知识库更重要的是可以反过来:
选择一个知识点 → 找到所有用到它的题 → 精确定位到每道题的具体步骤这对教学非常有价值。
比如老师想给孩子练“鸽巢原理”,传统方式可能只能靠人工筛题,或者根据题目分类大概查找。但很多题虽然用到了鸽巢原理,却不一定被标成“鸽巢原理题”。还有一些题只在某一个关键步骤用到了鸽巢原理,题目整体可能被归到组合、数论或构造类。
如果系统能把每道题的每一步都标注知识点,就可以精确查到:
哪些题用到了鸽巢原理;鸽巢原理出现在第几步;这一步是核心步骤还是辅助步骤;这道题除了鸽巢原理,还用了哪些其他知识点。
这样就能避免“分类不准”带来的问题。
三、对分层教学的帮助
这个系统对分层教学特别有意义。
不同孩子的水平不同,适合的题也不一样。传统题库的难度标签往往比较粗,比如:
简单中等困难
但实际教学中,难度并不是一个单独的数字。很多时候,一道题对某个孩子来说难,不是因为题目本身特别复杂,而是因为其中有一个知识点他没学过。
例如一个孩子已经学过:
整除奇偶性基础同余简单排列组合
但还没有学过:
图论不变量复杂归纳构造性下界
那么系统在给他选题时,就应该尽量避开包含未学知识点的题。
如果题库已经把每一道题拆成了步骤,并且每一步都标注了知识点,那么就可以做到:
只出孩子已经学过知识点范围内的题;避免突然出现没学过的知识点;按照知识点组合逐步增加难度;让孩子从基础知识点过渡到复合知识点;让练习路径更加平滑。
这样,题目就不再只是按照“章节”或“难度”粗略筛选,而是可以按照孩子真正掌握的知识结构来筛选。
四、对高水平学生的帮助:寻找“孤题”和稀有知识点
这个系统不仅适合基础学生,也适合高水平学生。
对于水平较高的孩子,普通练习题往往已经没有太大区分度。他们需要的不是大量重复基础题,而是一些能暴露盲区的题。
这里有一个很有用的概念:孤题。
所谓孤题,不是偏题怪题,而是指某些题中出现了比较少见的定理、技巧、结构或思路。这类知识点在题库中出现次数很少,但一旦遇到,往往能看出学生是否真正全面。
例如某个知识点在整个题库中只出现了 1 次或 2 次,那么这个知识点就很可能是一个稀有知识点。使用这种知识点的题,就很适合给高水平学生查漏补缺。
知识库可以统计:
哪些知识点出现次数很多;哪些知识点出现次数很少;哪些题包含稀有知识点;哪些稀有知识点只出现在高难度题中;哪些孩子从来没有练过某类稀有技巧。
五、未来可以实现的教学想象空间
当题目、步骤和知识点都结构化之后,题库就可以从“存题系统”升级为“教学分析系统”。
它未来可以实现很多有想象空间的功能。
1. 根据孩子已学知识点自动组题
系统可以记录孩子已经学过哪些知识点,然后自动筛选题目。
例如孩子已经掌握:
整除质因数分解同余奇偶性基础排列组合
系统就可以优先推荐只包含这些知识点的题。这样孩子练习时不会频繁遇到没学过的内容。
等孩子掌握更多知识点后,系统再逐步加入:
鸽巢原理构造法反证法数学归纳法不变量
练习路径就可以自然升级。
2. 自动判断一道题为什么难
一道题的难度不只是由题面决定的,而是由它的内部结构决定的。
未来可以根据这些指标综合判断难度:
步骤数量;核心知识点数量;辅助知识点数量;知识点是否稀有;是否跨多个大类;是否包含长推理链;是否需要构造;是否需要反证;是否需要归纳;是否有隐藏条件转化。
系统可以给出这样的解释:
这道题较难,因为它包含 20 个推理步骤;核心知识点包括数学归纳法、鸽巢原理和下界构造;其中“图连通性替代证明”在题库中出现较少;该题跨越组合、通用方法和图论思想。
这样难度就不再是一个黑盒数字,而是有理由、有来源的分析。
3. 根据薄弱知识点推荐题目
如果孩子经常在某类题中出错,系统可以反查这些错题背后的共同知识点。
例如孩子错了 10 道题,表面上看有数论题、组合题、代数题,但系统分析后发现,它们共同包含:
分类讨论反证法构造极端情况
这时系统可以专门推荐包含这些知识点的题,让孩子集中训练。
4. 自动生成学习路径
知识点之间是有层次关系的。
例如:
整除定义↓余数↓同余↓模运算性质↓二次剩余或更复杂的数论技巧
孩子可以先练基础知识点,再练两个知识点组合,最后练多个知识点融合的题。
这样就可以从“随机刷题”变成“有路径地学习”。
5. 自动生成错题分析报告
当孩子做错一道题时,系统可以不只是记录“错了”,而是分析:
错在第几步;这一用了什么知识点;这个知识点以前是否学过;这个知识点是否经常错;这道题是否包含未掌握知识点;是否需要回退到更基础的题。
例如系统可以生成:
这道题的关键错误发生在第 13 步。该步骤使用了鸽巢原理和反证法。孩子之前在鸽巢原理相关题目中的正确率较低。建议先补充 3 道基础鸽巢原理题,再回到本题。
这比简单显示标准答案更有教学价值。
6. 为老师提供备课辅助
老师备课时,可以通过知识点快速找题。
例如老师这节课要讲:
归纳法中的下界证明
系统就可以找出所有包含这个知识点的题,并且显示它们分别在哪一步使用了这个方法。
老师不需要从大量解析中手动筛选,直接就能看到:
题目 A:第 6 步使用;题目 B:第 12 步使用;题目 C:第 19 步使用;
这样备课效率会高很多。
7. 构建真正的数学知识图谱
当题目、步骤、知识点之间的关系逐渐积累起来后,就可以形成知识图谱。
图谱中的节点可以包括:
题目答案步骤知识点知识点大类定理方法难度层级
边可以表示:
题目包含步骤;步骤使用知识点;知识点属于某个大类;知识点之间存在依赖;题目之间共享知识点;某个知识点常与另一个知识点共同出现。
这样题库就可以从静态文本系统变成一个可以分析关系的知识网络。
六、这个样例最终做成了什么样子
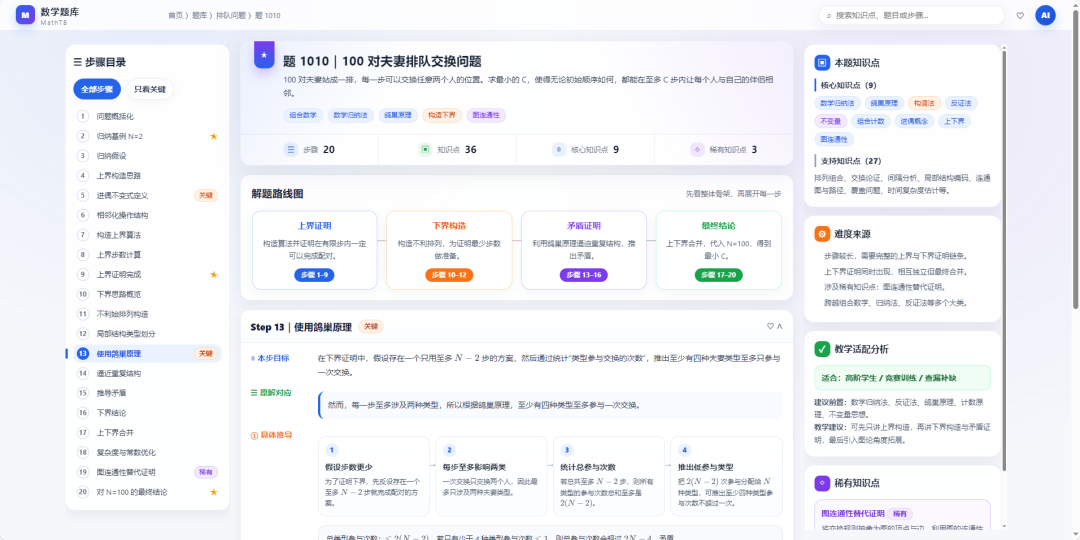
这个示例处理的是一道关于 100 对夫妻排队,通过交换位置使每对夫妻相邻 的组合题。
原题大意是:
100 对夫妻站成一排,每一步可以交换任意两个人的位置。求最小的 C,使得无论初始顺序如何,都能在至多 C 步内让每个人与自己的伴侣相邻。
这个样例最后被整理成了一个文件夹:
p1010_s785/
architecture.json
step_0001.json
step_0002.json
...
step_0020.json
其中:
architecture.json
保存的是整道题的总体解题架构。
而:
step_0001.json 到 step_0020.json
保存的是每一步的详细解释和知识点。
也就是说,这道题没有只保存成一整段解析,而是被拆成了 20 个清晰步骤。每一步都有中英文标题、中英文解释,以及对应的知识点。
例如这道题的 20 个步骤包括:
1. 问题概括化2. 归纳基例 N=23. 归纳假设4. 考察最左侧的两个人5. 条件性第一步交换6. 问题规模缩小7. 应用归纳假设8. 得出上界9. 构造最坏的初始排列10. 下界的基例 N=211. 假设存在更短的解法12. 关于最终位置奇偶性的观察13. 使用鸽巢原理14. 选取合适的类型 a15. 描述类型 a 的唯一交换形式16. 去除该孤立交换17. 得到矛盾18. 得出下界19. 下界的图连通性替代证明20. 对 N=100 的最终结论
这种结构非常适合后续教学使用。因为老师或系统可以清楚看到:这道题不是简单的“组合题”,它实际包含了归纳法、上界构造、下界证明、鸽巢原理、奇偶性观察、图连通性等多个知识点和方法。
七、制作流程总览
这个样例不是一次性生成的,而是分成两个主要阶段制作:
第一阶段:生成整道题的解题架构第二阶段:逐步生成每个步骤的详细解释和知识点
这样拆分很重要。
如果一次性要求 AI 完成“读题、理解答案、拆步骤、写解释、抽知识点”,容易出现步骤过粗、知识点漏掉、推理压缩等问题。
所以这里采用的是两段式制作方法:
先让 AI 从全局理解整道题,生成 architecture.json;再让 AI 按 architecture.json 逐步展开,生成 step_0001.json、 step_0002.json 等文件。
这种方法让结果更稳定,也方便后续断点续跑和人工检查。
八、第一阶段:制作整道题的解题架构
第一阶段的目标是生成:
architecture.json
这个文件不是详细解析,而是整道题的“解题地图”。
它保存了:
题目 ID;
答案 ID;
题目原文;
题目中文;
答案原文;
答案中文;
题目原有分类;
题目摘要;
整体解题策略;
预计涉及的大类;
步骤列表。
在这个样例中,题目原始分类包括:
组合数学
鸽巢原理
归纳法
不变量 / 单调量
这些分类不是最终知识点,但会作为背景信息传给 AI。这样 AI 在拆解时能知道这道题原本属于哪个方向。
architecture.json 的核心结构
示例中的 architecture.json 大致结构是:
{
"status":"architecture_completed",
"stage":"02_solution_architecture",
"problem_id":1010,
"solution_id":785,
"problem_markdown":"...",
"zh_markdown":"...",
"solution_markdown":"...",
"solution_zh_markdown":"...",
"categories":[
{
"category_id":5,
"path_en":"Discrete Mathematics > Combinatorics > Invariants / monovariants",
"path_zh":"离散数学 > 组合数学 > Invariants / monovariants",
"name_en":"Invariants / monovariants",
"name_zh":"Invariants / monovariants"
}
],
"problem_summary_en":"...",
"problem_summary_zh":"...",
"solution_strategy_en":"...",
"solution_strategy_zh":"...",
"estimated_major_categories_en":["Combinatorics", "General Methods"],
"estimated_major_categories_zh":["组合", "通用方法"],
"steps":[
{
"step_index":1,
"step_title_en":"Generalize the problem",
"step_title_zh":"问题概括化",
"step_goal_en":"...",
"step_goal_zh":"...",
"brief_content_en":"...",
"brief_content_zh":"..."
}
]
}
这里最重要的是 steps 字段。它给后续每一步详细生成提供了清晰的目录。
九、第一阶段使用的提示词
下面是第一阶段可以使用的提示词。这个提示词的目标是:不要生成完整细节,只生成整题架构和步骤目录。
02 解题架构生成提示词
你是一个数学题库知识库构建助手。
你的任务是阅读一道数学题及其答案解析,生成这道题的“解题架构”。
请注意:本阶段只需要生成总体架构,不要展开每一步的完整详细解释,也不要提取每一步的完整知识点。后续会有另一个阶段专门处理每个步骤的细节。
你需要根据题目、答案和数据库已有分类,完成以下任务:
1. 理解题目要求;
2. 总结题目核心目标;
3. 总结答案的总体解题策略;
4. 将答案拆成尽量清晰、细致、连续的步骤目录;
5. 每一步都要写清楚它在整道题中的作用;
6. 步骤不要过粗,如果一个推理过程包含多个逻辑转折,应拆成多个步骤;
7. 如果一道题需要 20 步才能讲清楚,就拆成 20 步;
8. 不要为了简短而合并关键推理;
9. 保留题目的数据库原始分类;
10. 所有重要字段都要同时给出英文和中文。
拆步骤时请遵守以下原则:
- 每一步应该只承担一个明确的推理任务;
- 上界证明和下界证明要分开;
- 构造、归纳、反证、分类讨论、关键观察都要单独成步;
- 如果答案中出现替代证明,可以标记为 optional;
- 不要添加与原答案无关的新证明;
- 可以补足原答案中省略但必要的逻辑连接;
- 不要改变原答案的数学结论。
请严格输出 JSON,不要输出 Markdown,不要输出解释文字。
输出格式如下:
{
"problem_summary_en":"Brief English summary of the problem.",
"problem_summary_zh":"题目的中文简要概括。",
"solution_strategy_en":"Overall English strategy of the solution.",
"solution_strategy_zh":"答案整体解题策略的中文说明。",
"estimated_major_categories_en":[
"Combinatorics",
"NumberTheory",
"Algebra",
"Geometry",
"Inequality",
"GeneralMethods"
],
"estimated_major_categories_zh":[
"组合",
"数论",
"代数",
"几何",
"不等式",
"通用方法"
],
"steps":[
{
"step_index":1,
"step_title_en":"Short English title of this step.",
"step_title_zh":"该步骤的中文标题。",
"step_goal_en":"What this step is trying to achieve.",
"step_goal_zh":"该步骤要完成什么目标。",
"brief_content_en":"Brief English description of the reasoning in this step.",
"brief_content_zh":"该步骤推理内容的中文简述。",
"depends_on":[]
}
]
}
下面是题目信息:
Problem ID:
{{problem_id}}
Solution ID:
{{solution_id}}
Original Problem:
{{problem_markdown}}
Chinese Problem:
{{zh_markdown}}
Original Solution:
{{solution_markdown}}
Chinese Solution:
{{solution_zh_markdown}}
Database Categories:
{{categories}}
这个提示词的重点是:只做架构,不做每一步细节。
它会强制 AI 先从整体上理解题目,再把解题过程拆成稳定的步骤目录。
十、第二阶段:制作每一步的详细解释和知识点
第二阶段读取第一阶段生成的 architecture.json。
然后对每个步骤分别处理,生成:
step_0001.json
step_0002.json
step_0003.json
...
这样每一步都是一个独立文件。
在示例中,一共生成了 20 个步骤文件。
每个步骤文件包含:
步骤标题;
步骤内容;
详细解释;
该步骤在整体证明中的作用;
该步骤用到的知识点;
知识点英文名;
知识点中文名;
知识点别名;
知识点大类;
知识点细分分类;
知识点说明;
相关公式;
知识点重要程度。
单个 step 文件的结构
例如某一步文件大致是:
{
"status":"step_detail_completed",
"stage":"03_step_detail",
"problem_id":1010,
"solution_id":785,
"step_index":2,
"step_count":20,
"step_title_en":"Base case for induction (N=2)",
"step_title_zh":"归纳基例(N=2)",
"step_text_en":"List all distinct initial orders for two couples...",
"step_text_zh":"列出两对夫妻的所有不同初始排列...",
"explanation_en":"Because there are only two couples, any arrangement is a permutation...",
"explanation_zh":"由于只有两对夫妻,任何排列都是多重集合的排列...",
"raw_knowledge_points":[
{
"raw_kp_id":"rawkp_p1010_s785_st0002_k01",
"name_en":"Mathematical Induction – Base Case",
"name_zh":"数学归纳法——基例",
"aliases_en":["Induction Base Case"],
"aliases_zh":["归纳基例"],
"major_category_en":"General Methods",
"major_category_zh":"通用方法",
"category_guess_en":"General Methods / Induction",
"category_guess_zh":"通用方法/归纳",
"summary_en":"Verifies that the statement holds for the smallest non-trivial value.",
"summary_zh":"验证命题在最小的非平凡情形下成立,为归纳证明提供起点。",
"formula":"",
"importance":"core"
}
]
}
这里的 raw_knowledge_points 是原始知识点记录。
之所以叫 raw,是因为这个阶段不急着合并知识点。例如:
数学归纳法基例
归纳基例
Induction Base Case
Base Case of Induction
这些可能最终会合并成同一个正式知识点,但在当前阶段先全部保存原始记录。
十一、第二阶段使用的提示词
下面是第二阶段的提示词。它的目标是:针对 architecture.json 中的一步,生成该步骤的详细解释和知识点。
03 步骤详情生成提示词
你是一个数学题库知识库构建助手。
现在你需要根据一道题的整体解题架构,详细展开其中的某一个步骤。
请注意:你只处理当前这一步,不要重新拆整道题,不要跳到其他步骤,不要省略本步骤中的关键推理。
你的任务包括:
1. 写出当前步骤的英文内容;
2. 写出当前步骤的中文内容;
3. 写出当前步骤的英文详细解释;
4. 写出当前步骤的中文详细解释;
5. 说明该步骤在整个解法中的作用;
6. 提取该步骤中实际使用到的数学知识点;
7. 每个知识点都要有英文名、中文名、英文说明、中文说明;
8. 每个知识点都要标注大类;
9. 每个知识点都要标注更细的分类猜测;
10. 如果有公式,要用 LaTeX 写出;
11. 标注该知识点在本步骤中是 core 还是 supporting。
知识点大类请优先从下面选择:
英文大类:
- Number Theory
- Algebra
- Combinatorics
- Geometry
- Inequality
- Functions
- Equations
- Probability
- Logical Reasoning
- Mathematical Induction
- Graph Theory
- General Methods
- Other
中文大类:
- 数论
- 代数
- 组合
- 几何
- 不等式
- 函数
- 方程
- 概率
- 逻辑推理
- 数学归纳法
- 图论
- 通用方法
- 其他
提取知识点时请遵守:
- 只提取当前步骤真正用到的知识点;
- 不要把整道题所有知识点都塞进当前步骤;
- 如果一个步骤用了多个知识点,要全部列出;
- 核心知识点标为 core,辅助知识点标为 supporting;
- 知识点名称要尽量稳定、简洁、可复用;
- 英文名用 Title Case;
- 中文名要自然、适合教学;
- 不要在当前阶段尝试匹配已有知识库;
- 不要合并相似知识点;
- 每一次出现都作为 raw knowledge point 保存;
- 后续会统一做知识点去重和合并。
请严格输出 JSON,不要输出 Markdown,不要输出解释文字。
输出格式如下:
{
"step_text_en":"Detailed English statement of this step.",
"step_text_zh":"该步骤的中文详细表述。",
"explanation_en":"Detailed English explanation of why this step is valid and necessary.",
"explanation_zh":"该步骤为什么成立、为什么需要这样做的中文详细解释。",
"role_in_solution_en":"The role of this step in the whole solution.",
"role_in_solution_zh":"该步骤在整个解法中的作用。",
"raw_knowledge_points":[
{
"name_en":"Knowledge Point Name in English",
"name_zh":"知识点中文名",
"aliases_en":["Alternative English name"],
"aliases_zh":["中文别名"],
"major_category_en":"Combinatorics",
"major_category_zh":"组合",
"category_guess_en":"Combinatorics / Pigeonhole Principle",
"category_guess_zh":"组合 / 鸽巢原理",
"summary_en":"Short English explanation of this knowledge point.",
"summary_zh":"该知识点的中文简要说明。",
"formula":"LaTeX formula if any, otherwise empty string",
"importance":"core"
}
]
}
下面是整道题信息:
Problem ID:
{{problem_id}}
Solution ID:
{{solution_id}}
Original Problem:
{{problem_markdown}}
Chinese Problem:
{{zh_markdown}}
Original Solution:
{{solution_markdown}}
Chinese Solution:
{{solution_zh_markdown}}
Database Categories:
{{categories}}
下面是整道题的解题架构:
{{architecture_json}}
现在只处理这一步:
Step Index:
{{step_index}}
Step Title English:
{{step_title_en}}
Step Title Chinese:
{{step_title_zh}}
Step Goal English:
{{step_goal_en}}
Step Goal Chinese:
{{step_goal_zh}}
Brief Content English:
{{brief_content_en}}
Brief Content Chinese:
{{brief_content_zh}}
这个提示词的关键是限制 AI:只展开当前步骤,不要重新发明整题结构。
这样可以保证每个步骤文件和 architecture.json 中的步骤目录一致。
十二、为什么要分成 architecture 和 step 两层
这个样例最重要的制作思路就是:先整体,后局部。
如果直接让 AI 一次性生成所有步骤详情,容易出现几个问题:
步骤数量不稳定;
前面步骤详细,后面步骤变粗;
知识点容易漏;
很长的题可能输出不完整;
出错后需要整题重跑。
分成两层以后,每一层任务都更清楚。
第一层只负责:
读懂整道题;
拆出合理步骤;
形成解题地图。
第二层只负责:
根据某一步的目标;
写清楚这一步;
解释这一步;
提取这一步知识点。
这样做出来的结构更稳定。
在这个样例中,architecture.json 把原始答案拆成了 20 步。然后第二阶段逐步展开,得到 20 个 step 文件。每一步都能单独检查、单独修改、单独重跑。
十三、示例中的知识点是怎样生成的
以“归纳基例 N=2”这一步为例,系统从这一步中提取出了多个知识点,包括:
数学归纳法——基例多重集合的排列夫妻相邻要求换位(交换)操作
这说明系统不是只给整道题贴一个“组合”标签,而是能看出这一步内部实际用了什么。
对于这一步来说:
数学归纳法——基例是核心知识点,因为它是归纳证明的起点。
多重集合的排列是辅助知识点,因为列出两对夫妻的排列时用到了这种思想。
夫妻相邻要求是题目条件对应的结构性知识点。
换位(交换)操作是题目允许操作的形式。
这些知识点都被保存在当前步骤文件中,并带有中英文说明。
这样以后反查时,不只是知道“这道题用了归纳法”,而是可以定位到:
第 2 步使用了归纳基例;第 13 步使用了鸽巢原理;第 19 步使用了图连通性;第 20 步完成 N=100 的最终代入。
十四、知识点大类的设计
每个知识点都保存两个层次的分类。
第一层是大类:
{
"major_category_en": "Combinatorics",
"major_category_zh": "组合"
}
第二层是更细的分类猜测:
{
"category_guess_en": "Combinatorics / Pigeonhole Principle",
"category_guess_zh": "组合 / 鸽巢原理"
}
这种设计比单纯保存一个分类更灵活。
大类适合做统计和筛题,比如:
只看组合题;排除几何题;找同时涉及组合和图论的题;统计某个孩子最近练习中数论题占比。
细分类适合做知识点归并和教学讲解,比如:
鸽巢原理;数学归纳法;图连通性;最坏情况构造;交换操作;下界证明。
十五、为什么要保留中英文
这个样例中,题目、步骤、解释、知识点都尽量保存中英文两套字段。
这样做有几个实际好处。
第一,英文原题和英文解析可以保留原始语义,避免翻译损失。
第二,中文字段方便教学展示,老师和学生可以直接阅读。
第三,知识点中英文对应以后,后续做搜索时更方便。例如搜索“鸽巢原理”或 “Pigeonhole Principle” 都可以找到同一类内容。
第四,中英文同时存在,也方便后面生成双语讲义或双语题库页面。
十六、为什么每一步单独保存 JSON
示例中没有把所有步骤只放在一个大文件里,而是把每一步单独保存成:
step_0001.json
step_0002.json
...
step_0020.json
这样做有几个好处。
首先,方便检查。哪一步有问题,就打开哪一步。
其次,方便重跑。如果第 13 步的知识点提取得不好,只需要重跑第 13 步,不需要整道题全部重做。
再次,方便反查。每个知识点都能精确定位到某个题目、某个答案、某个步骤。
最后,方便入库。后面如果要把数据放进数据库,可以直接把每个 step 文件作为一条步骤记录,把里面的 raw_knowledge_points 写入知识点关系表。
十七、这个样例已经实现的效果
通过这个制作流程,一道普通的数学题被整理成了结构化数据。
原始题目只是:
题目 + 答案 + 分类整理后变成了:
题目答案原始分类题目摘要整体解题策略20 个解题步骤每一步的详细解释每一步的知识点每个知识点的大类每个知识点的中英文说明
这种结构已经可以支持很多教学场景。
比如基础学生练习时,可以根据知识点筛题,避免出现没学过的内容。
比如优秀学生拔高时,可以找出现频率低的知识点对应的题,用来查漏补缺。
比如老师备课时,可以直接看到一道题的推理结构,而不是从一整段解析中手动拆解。
比如做题库统计时,可以知道哪些知识点出现频繁,哪些知识点比较稀有。
十八、复现这个样例时的关键注意点
如果要复现这个制作方法,最重要的不是代码命令,而是以下几个设计原则。
第一,题目数据要保留完整。
不要只保留中文题目,也不要只保留答案结论。最好同时保留:
题目原文;题目中文;答案原文;答案中文;数据库原有分类。
第二,先生成解题架构,不要一开始就生成所有细节。
architecture.json 是后面所有步骤的基础。它决定了这道题会被拆成多少步,每一步的目标是什么。第三,每一步单独生成详细解释和知识点。
这样步骤会更细,质量更稳定,也方便后续修改。
第四,知识点先保存 raw 版本,不要急着合并。
同一个知识点可能有不同表达方式,先全部保留,后面再统一整理更稳。
第五,所有关键字段都保留中英文。
这样既适合教学展示,也方便后面做搜索和整理。
第六,知识点必须绑定到步骤,而不是只绑定到题目。
因为一题可能包含多个知识点,如果只给整道题打标签,就无法知道知识点具体在哪里使用。绑定到步骤以后,反查才真正有价值。
十九、总结
这个样例展示的是一种把数学题目解析结构化的方法。
它的制作过程可以概括为:
先保存完整题目和答案;再生成整题解题架构;再逐步展开每个步骤;再从每一步中提取知识点;最后形成可以反查的步骤知识点数据。
这样得到的数据不再只是普通解析,而是可以用于教学筛题、知识点回查、分层练习和查漏补缺的结构化知识库。
它最核心的价值是:
题目可以按知识点查;知识点可以反查到题目;每个知识点可以定位到具体步骤;孩子练习时可以避开没学过的知识点;高水平孩子可以通过稀有知识点题目查漏补缺。
因此,这套制作方法不仅是在整理题目,而是在把题库改造成一个真正可用于教学分析和个性化训练的数学知识系统。
猜一下我这个文章为什么归类到了 数论证明器 里面。